


このコラム記事では2022年11月に行われたスターキージャパン30周年記念 補聴器販売従事者向けセミナーにて、スターキーCTOアーチン・ボーミック博士が講演内で取り上げた自身の論文を複数回にわたってご紹介していきます。
補聴器の現在(いま)までと、未来の補聴器の姿を
最新テクノロジーを通してお伝えします。

AIと機械学習
近年、新しいコンピューティングのパラダイムが急速に普及しています。
このパラダイムは、あらかじめ定義されたルールでシステムをプログラミングするのではなく、データを使ってシステムをトレーニングするというものです。
このパラダイムは、人間の知覚、認識、知能の研究に着想を得たものです。
これらのシステムやアプリケーションは、私たち人間が経験や周囲の環境から得た情報から学ぶのと同じように、データから学習するように設計されています。(下図)
このような機械学習をベースとした新しい知的システムの出現は、かなり以前から想定されていました。1955年のダートマス大学のワークショップでは、AIという言葉が提唱され16、「学習のあらゆる側面や知能のあらゆる特徴は、機械がそれをシミュレートできるほど正確に記述できる」と断言されました。
このビジョンは、機械学習アルゴリズム、超並列コンピューティングアーキテクチャ、データの大規模なデジタル化における驚異的な開発ペースによって、現在、現実のものとなりつつあり、多くの自律的かつインタラクティブな技術を可能にしています17。
現在、AIは、聴覚や明瞭度の機能強化のみならず、新しい機能を付加して補聴器を未来に推進しつつあります。機械学習技術に基づき、補聴器はどの音が重要かを判断し、その音だけを増幅するように自動調整することができます。その音だけを増幅させ、周囲の騒音を抑制するように自動的に調整できるのです。
例えば、交通量の多い通りに面した喫茶店で、友人と一緒に座っているとします。このような環境では、会話や他の人の話し声、交通騒音、頭上の飛行機の音など、あらゆる雑音が存在します。
現在の補聴器は、搭載されたAI技術によって、このような雑音のある環境を理解することができます。様々な音を分離・識別し、会話を増幅し、音声を明瞭にし、周囲の雑音を低減します。超人的な聴覚能力を与えてくれるのです。
音響環境分類:音の認識
聴覚シーン分析18 から派生した音響環境分類(AEC)は、聴覚システムが実際の聴き取り環境で個々の音を分離する能力を模倣するために信号処理を使用する計算プロセスです。AECは、主に時間的および空間的な特徴に基づいて、音を個別の「シーン」または環境に分類します19。
現代の補聴器は、AECを利用して聴取環境(静かな場所、リビング、レストラン、講堂など)を分類し、自動的に最も適したサウンドマネジメント機能(指向性マイク、雑音抑制、ハウリング抑制など)を有効にします20。
多くの AEC システムでは、特徴抽出と特徴・パターン分類、処理と音響環境分類の2つの処理段階を組み合わせています(図 5)。
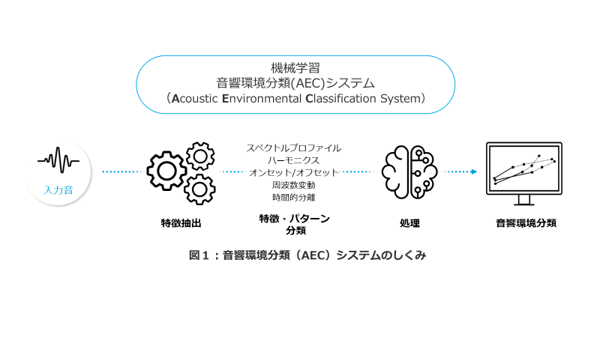
AECシステムの精度は、特徴量、音のクラス、使用する統計モデルの数に依存します。分類精度を向上させるために、大規模なデータセットで学習させた「教師あり機械学習モデル」が採用されています。例えば、スターキーが開発したAECシステムでは、8つの自動音響分類を備えています。
音楽、静かな場所での会話、大きな騒音下での会話、騒音下での会話、機械音、風切音、騒音、静寂という8つの自動音響クラスがあります。それぞれのクラスに適した利得、圧縮、指向性、雑音抑制などの調整を行い、騒音下での会話の明瞭度を優先させます。多くの補聴器システムの分類精度は80~90%で、圧縮されたポップミュージック、強く反響する音声、音色や揺らぎのあるノイズなどは分類に問題が発生する場合もあります。このため、大量のデータを用いた機械学習による自動調整でさえも、特に困難な聴取環境では必ずしも十分ではありません。22
このような状況では、ユーザーによるオンデマンド分析と自動調整を行うことで、音声の明瞭度を向上させる方が効果的な場合があります。
エッジAI:音声理解を促進する
騒がしい環境での会話を理解することは、多くの人にとって難しいことですが、聴覚障害者にとっては特に難しいことです。33
したがって、自動的な音響分類や調整だけでなく、ユーザーによって選択され、開始される積極的な音声強調アルゴリズムも、聴き取りが難しい状況に直面したときに非常に役に立ちます。
このような機能は、ダブルタップやプッシュボタンなどの操作により、ユーザーが開始できるような、シンプルなインターフェイスであることが理想的です。
そうすることで、補聴器は聴取環境の「音響スナップショット」を取得し、それに応じてパラメータを調整することで、音声の明瞭度を最適化することができるのです。
私たちは、音声の明瞭度を高めるために、オンデマンドのエッジコンピューティングソリューションを開発しました。デバイスのダブルタップジェスチャーは、MEMS(Micro Electromechanical System)ベースのモーションセンサーによって検知されます。23
↑タップコントロールの方法
オンデマンドかつアダプティブなパラメータ調整には、ゲインオフセット、ノイズマネージメント設定、指向性マイク設定、風切音抑制などが含まれます。スマートフォンやクラウドへの接続は不要で、すべての計算能力は「補聴器」で処理、実現されます。
レストランや自動車、残響のある環境でのコミュニケーションにおいて、ほとんどのユーザーがこのモードを操作しやすく、オージオグラムに基づく補聴器設定よりも好んで使用したとの研究結果があります(下図)。24
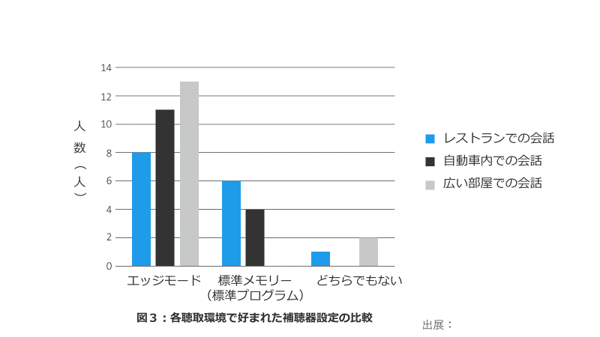 聴覚障害者15名のオンデマンド調整と規定のプログラムとの嗜好比較
聴覚障害者15名のオンデマンド調整と規定のプログラムとの嗜好比較
COVID-19のパンデミックの際、保健所や政府関係者が空気感染を減らすために地域全体のマスク着用を奨励または義務付けました。
この習慣は、ソーシャルディスタンス(社会的距離)を置くことでウイルスの拡散を遅らせましたが、特に難聴者にとって、明確で共感できるコミュニケーションの障壁となりました。26 スターキーはマスクを通して音がどのように減衰するか、聴覚障害者の音響測定によって評価しました。下図は、さまざまなタイプのマスクの違いを示しています。
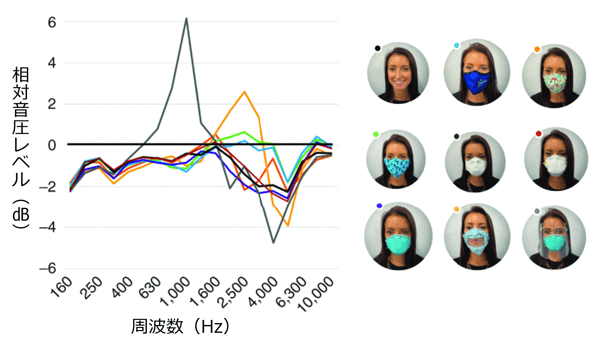
データはマスクを着用しない条件で正規化されています。結果として、すべてのマスクが重要な高周波数情報を減少させる一方で、布製、医療用、紙製マスク、特にプラスチック製の窓が付いたマスクには大きなばらつきがあることが示唆されました。
予想外だったのは、透明なプラスチックパネルを装着したマスクやシールドでは、低・中音域が数デシベル増強され、高音域が低下することでした。これらのデータはマスクの使用による影響を考慮して、高周波数の利得調整を固定することの持つ難しさを物語っています。
これらの知見から、スターキー補聴器では、ユーザーによるマスクの自動評価・調整機能を開発することになりました。オリジナルモードは、機械学習によって学習したAIモデルを搭載し、音声と雑音のレベルを評価することで、音声の明瞭度と音質を最適化します。
マスク用エッジモードは、利得、出力、ノイズマネジメント、指向性マイクなど、複数の機能パラメーターを動的に調整します。
そのため、他の「マスクモード」プログラムで使用されている単純なゲインオフセットとは異なり、どのマスクを装着しているか、コミュニケーション相手との距離、背景雑音の有無に「不可知論的」なものとなっています。必要な信号処理はすべて耳元で行われ、スマートフォンやクラウドへの接続は不要で補聴器の演算処理で行われます。
補聴器ユーザーを対象とした実験では、AIによる音声処理、「手動」マスクモードオフセットプログラムの両方が、「標準プログラム」よりも大幅に補聴器ユーザーに好まれました。
また、話し手が医療用N95マスクを使用している場合、「通常」の処方目標よりも補聴器ユーザーに好まれました。現在進行中の研究では、さまざまなマスクにおいて、エッジモードとマスクモードオフセットプログラムのどちらが好まれるかを評価しています。
補聴器のプロセッサで実行されるアルゴリズムに加えて、ディープニューラルネットワーク(DNN)アーキテクチャに基づく音声強調戦略も新たに登場しています。
DNNは、スマートフォンなどのウェアラブル機器やモバイル機器に搭載されている計算処理能力の向上と、対象音に近いデバイスのマイクを入力ソースとして使用できる利点を兼ね備えています。
機械学習分野の特殊なサブカテゴリとして、DNNアーキテクチャは、ニューロンと呼ばれる相互に接続された計算ノードの多層構造の計算機を使用します。
各層は、ネットワークの "幅 "を表す多数のニューロンで構成され、層の数は "深さ "を定義します。人間の大脳皮質は、相互に接続された膨大な数の生物学的ニューロンから構成されており、これによって、高度化する階層構造の中で多くの感覚情報を処理することができます。
大脳皮質は、複雑なパターンや相関関係を導き出し、人間が世界を理解し、ナビゲートするのを助けています。大脳皮質の構造と機能にインスパイアされたDNNベースのAIシステムは、以前は人間の知性によってのみ対処可能と考えられていた問題を解決するようになってきています。17
研究により、さまざまな SN比や騒音下において、音声品質を維持しながら音声明瞭度を向上させる DNN の価値が実証されています。42, 43
下図は、2020 年に導入された DNN ベースの音声強調機能の概略図です。44
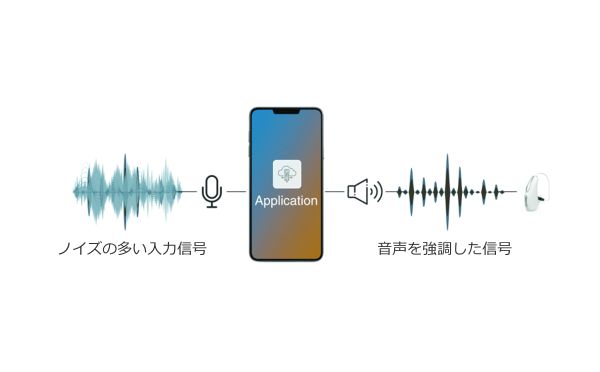
ボイスAIの機能概略図
また、追加解析により、難聴レベルとこのアルゴリズムの好みの間に正の相関関係があることが明らかになりました。また、難聴レベルが高い補聴器ユーザーは、SN比が向上するのであれば、スマートフォンへのアルゴリズム処理の「オフボード化」によって生じるシステム遅延の原因となる信号処理の複雑化を許容し、難聴レベルの低いユーザーは、さらなる遅延を許容する可能性は低いことが示唆されました。そのため、本機能は高度から重度難聴のユーザーにのみ推奨されます。
補聴器がどのように役立つのか、ご自身の耳で確かめてみませんか?
ここに郵便番号を入力するだけで、最新の補聴器技術を紹介、試聴可能なお近くの補聴器専門店のリストを表示します。(補聴器の試聴には費用がかかる場合があります。)
*元になっている学術論文は下記からご確認いただけます。
IEEE(電気電子技術者協会)
https://ieeexplore.ieee.org/document/9585189
出典:
17. A. Bhowmik, “Artificial intelligence:From pixels and phonemes to semantic understanding and interactions,” in Proc. Int. Display Workshops, 2019, 26, 9-12.doi:10.36463/idw.2019.0009.
18. A. S. Bregman, Auditory Scene Analysis: The Perceptual Organization of Sound. Cambridge, MA: The MIT Press, 1990.
19. T. Zhang and J. S. Kindred, System for evaluating hearing assistance device settings using detected sound environment. U.S. Patent 2007/0217620 A1, Sept. 20, 2007.
20. D. Fabry and J. Tchorz, “Results from a new hearing aid using “acoustic scene analysis,” Hearing J.,vol. 58, no. 4, pp. 30–36, 2005.doi: 10.1097/01.HJ.0000286604.84352.42.
22. J. J. Xiang, M. F. McKinney, K. Fitz,and T. Zhang, “Evaluation of sound classification algorithms for hearing aid applications,” in Proc. IEEE Int.Conf. Acoustics, Speech Signal Process.,2010, pp. 185–188.
24.J. Harianawala, M. McKinney, and D. Fabry, “Intelligence at the edge,”Starkey White Paper, 2020. https://starkeypro.com/pdfs/technical-papers/Intelligence_at_the_Edge_White_Paper.pdf
26.D. Fabry, T. Burns, M. McKinney,and A. Bhowmik, “Unmasking”benefits for hearing aid users in challenging listening environments,” Hearing Rev., vol. 27, no. 11,pp. 18–20, 2020
33.L. Jorgensen and M. Novak,“Factors influencing hearing aid adoption,” Seminars Hearing,
vol. 41, no. 1, pp. 6–20, 2020. doi:10.1055/s-0040-1701242.
42.Y. Zhao, D. Wang, I. Merks, and T.Zhang, “DNN-based enhancement of noisy and reverberant speech,”in Proc. IEEE Int. Conf. Acoustics,Speech Signal Process. (ICASSP),
2016, pp. 6525–6529. doi: 10.1109/ICASSP.2016.7472934.
43. Y. Zhao, B. Xu, R. Giri, and T. Zhang,“Perceptually guided speech enhancement using deep neural networks,” in Proc. IEEE Int. Conf.Acoustics, Speech Signal Process.(ICASSP), 2018, pp. 5074–5078.
44. D. Cook, “AI can now help you hear speech better,” Hearing Loss J.,2020. [Online]. Available: https://www.hearinglossjournal.com/ai-can-now-help-you-hear-speech/





